下面是一个 带图文 / 步骤 的 Ollama 在 Windows 上安装与配置教程 —— 从下载、安装、环境变量设置、模型下载到第一次运行,全流程覆盖(适合新手)。如果你跟着做,一般 10–20 分钟就能跑起来。
✅ 一、前置条件与准备
- Windows 系统:推荐 Windows 10 22H2 / Windows 11 或更高版本。 (Ollama 文档)
- 若你机器有 NVIDIA 显卡 或 AMD Radeon 显卡,建议驱动为最新(NVIDIA ≥ 452.39);这样 Ollama 才能利用 GPU 加速。 (Ollama 文档)
- 硬盘 / 存储空间:Ollama 本身占用约 4 GB,大型语言模型可能为几十 GB 到上百 GB — 如果默认用户目录空间不足,建议准备额外空间或使用大盘。 (Ollama 文档)
📥 二、下载安装包并安装



步骤
- 打开浏览器,访问 Ollama 官网 → 下载页,点击 “Download for Windows” → 得到
OllamaSetup.exe。 (Oryoy) - 双击运行
OllamaSetup.exe,按提示安装即可。默认安装目录为当前用户目录。安装过程中不需要管理员权限。 (Ollama 文档) - 安装完成后,你会看到系统托盘中出现 Ollama 图标,表示它正在后台运行。 (博客园)
💡 可选:如果你不想使用默认安装目录,在命令行中执行:
OllamaSetup.exe /DIR="D:\Your\Path\Ollama"这样就能把 Ollama 安装到你指定位置。 (Ollama 文档)
🔧 三、配置模型存储位置(可选,但推荐)
默认情况下,Ollama 会把下载的模型存到用户目录。如果你希望存到别的盘,比如 D 盘(避免 C 盘爆满):
- 打开 Windows 设置 → 搜索 “环境变量” → 编辑你的用户环境变量。 (Ollama 中文文档)
- 新建环境变量:
- 变量名(Name):
OLLAMA_MODELS - 变量值(Value):你希望存储模型的目录路径,如
D:\ollama_models。 (Ollama 中文文档)
- 变量名(Name):
- 保存后,退出 Ollama(托盘图标右键退出),然后重新启动 Ollama,使配置生效。 (Ollama 中文文档)
这样,你下载的大模型就会存到你指定的目录,不会占用系统盘。
🧪 四、验证安装是否成功 & 初次使用
4.1 验证命令行工具是否有效
打开 CMD 或 PowerShell,输入:
ollama --version
如果输出版本号,例如 0.5.x 类似内容,就说明安装成功,可以用 CLI 操作。 (博客园)
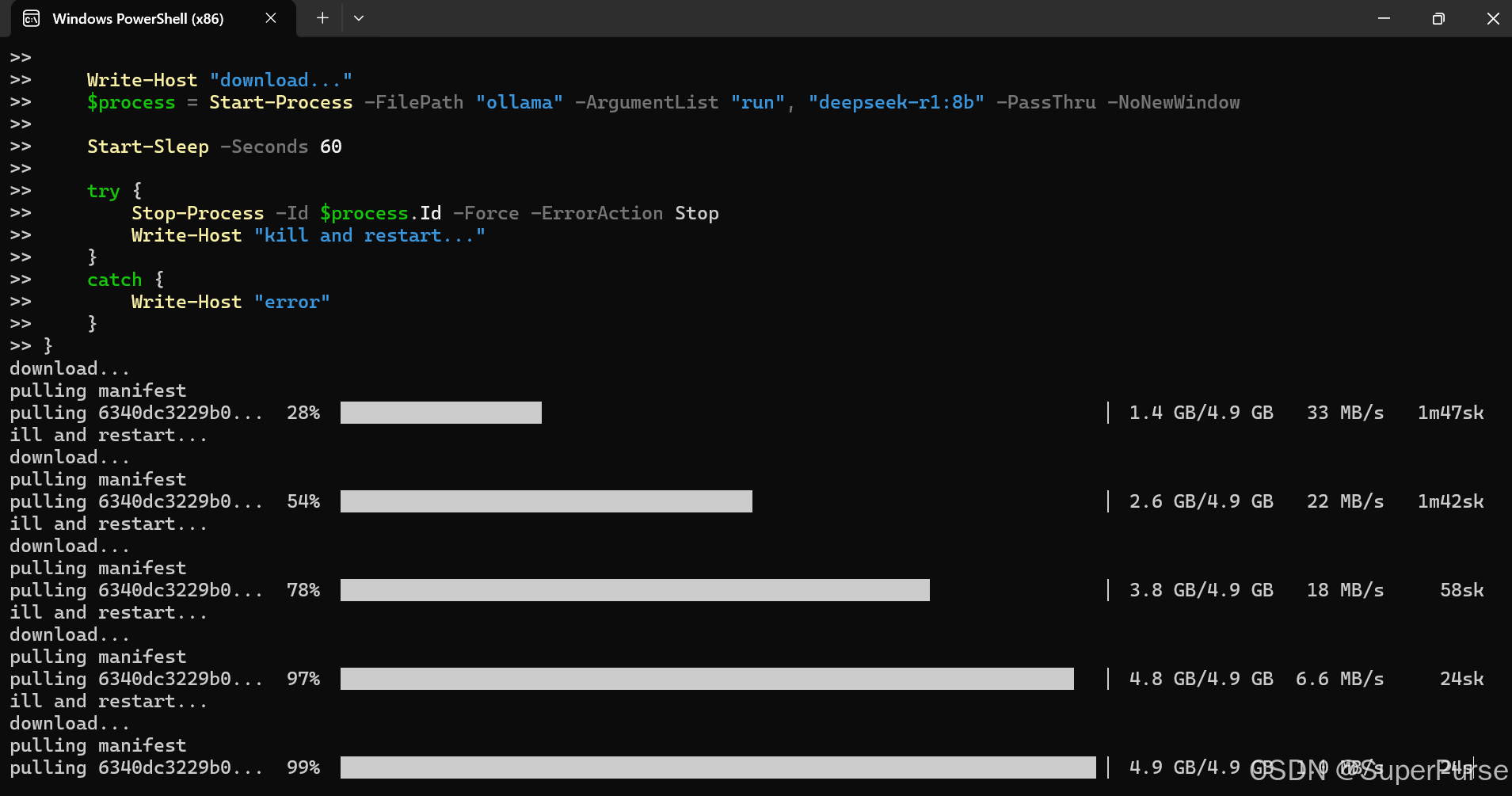
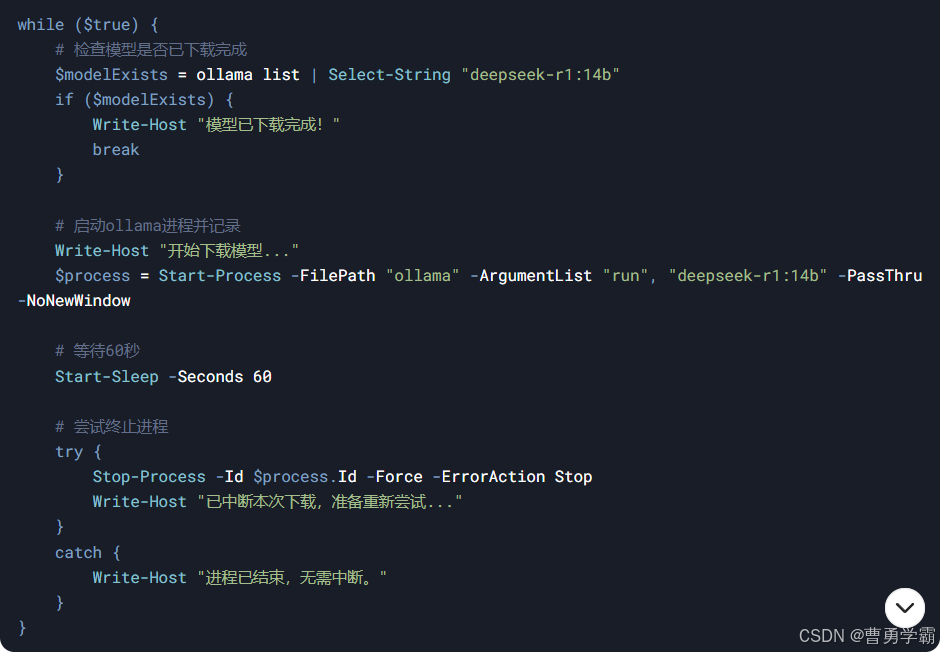
4.2 拉取一个模型 (例如 7B 或者你需要的)
例如:
ollama pull <model-name>
注意:模型较大,首次下载可能需要较长时间和较大空间。
4.3 启动模型 / 本地服务
你可以直接启动一个模型试试:
ollama run <model-name>
或者启动一个 HTTP API 服务,方便 web 或脚本调用:
ollama serve
默认情况下,API 会监听在 http://localhost:11434。 (Ollama 中文文档)
🔄 五、常见配置修改 & 进阶设置
| 目的 | 操作 / 配置方法 |
|---|---|
| 更改安装目录 | 安装时用 /DIR="..." 参数 (Ollama 文档) |
| 更改模型存储目录 | 设置用户环境变量 OLLAMA_MODELS 为目标路径 (Ollama 中文文档) |
| 使用 GPU 加速(NVIDIA / AMD) | 确保显卡驱动已安装且更新,然后启动模型即可自动检测 GPU。 (Ollama 文档) |
| 在脚本 / API 中调用模型 | 使用 ollama serve + REST API,或 CLI + 自定义脚本 / WebUI。 (Ollama 中文文档) |
📷 整体安装配置流程图(方便回顾)


🧠 六、常见问题与对应解决建议
| 问题 | 可能原因 / 解决办法 |
|---|---|
ollama --version 没有响应 | 安装未成功 / PATH 未加到环境变量 → 重装 + 确认 PATH |
| 模型下载失败 / 空间不足 | 磁盘空间不足 → 更改 OLLAMA_MODELS 路径 / 清理空间 |
| 启动模型失败 / 无法识别 GPU | 驱动版本过旧或显卡不受支持 → 更新驱动 / 使用 CPU 推理 |
| REST API 调用报错 404 / 无响应 | 服务未启动 → 确认 ollama serve 运行 / 端口被防火墙阻止 → 允许 11434 端口 |
| 模型加载很慢 / 卡顿 | 模型过大 + 硬件资源不足 → 使用较小模型 / 增加内存或换 SSD |
✅ 七、总结
- 在 Windows 上安装 Ollama 非常简单:下载官方安装包 → 双击安装 → 可选配置模型存储路径
- 配置好之后,就可以用命令行或 REST API 本地运行大型语言模型 (LLM) —— 既方便又私有,不依赖云服务
- 如果你有 GPU + 足够资源,性能会更好,适合长期运行、自建工具、脚本化调用
发表回复